Example
Consider a 'sales_data' table with the columns 'product', 'region', and 'sales'. To find the total sales per product for each region, you can use the PIVOT operator as follows:
SELECT *
FROM
(SELECT product, region, sales
FROM sales_data)
PIVOT
(SUM(sales)
FOR region IN ('North' AS north, 'South' AS south, 'East' AS east, 'West' AS west)
)
ORDER BY product;
This query will return a result set with columns 'product', 'north', 'south', 'east', and 'west', displaying the total sales per product for each region in a clear and concise manner.
While the standard PIVOT operation works well with a known number of columns or categories, it may not be suitable for scenarios where the number of columns or categories is not fixed or known in advance. This is where dynamic pivot comes into play. Dynamic pivot is a technique that enables you to pivot data on the fly, generating the necessary columns based on the distinct values present in the data set.
Dynamic pivot is a powerful tool for handling various data scenarios where the structure of the data is not fixed or can change over time. By using dynamic pivot, you can create more flexible and adaptable queries that can handle a wide range of data inputs, making your applications more robust and maintainable. Additionally, dynamic pivot allows you to generate complex reports and visualizations without having to manually modify your queries every time the data structure changes.
Dynamic Pivot with XML Functions
Oracle provides a set of powerful XML functions that can be used to manipulate and transform XML data within SQL queries. Some of the key XML functions include XMLAGG, XMLELEMENT, and XMLFOREST, which allow you to aggregate, generate, and format XML elements, respectively. By leveraging these XML functions in combination with other SQL constructs, you can create dynamic pivot queries that can adapt to varying data structures and generate pivoted results without knowing the column names in advance.
In the context of dynamic pivoting, there isn't a single "common syntax" for XML functions in Oracle, as they can be combined in various ways to achieve the desired output. However, I can provide you with a general structure of how these XML functions are typically used in dynamic pivot scenarios:
XMLELEMENT
This function is used to create an XML element with a specified name and content. The general syntax is:
XMLELEMENT(NAME element_name, value_expression)
XMLATTRIBUTES
This function is used to add attributes to an XML element. The general syntax is:
XMLATTRIBUTES(expression AS attribute_name [, ...])
XMLAGG
This function is used to aggregate multiple XML elements into a single XML fragment. The general syntax is:
XMLAGG(xml_expression)
In a dynamic pivot scenario, these functions are usually combined in a nested fashion, like this:
XMLELEMENT(
NAME "element_name",
XMLATTRIBUTES(expression AS attribute_name),
value_expression
)
And then aggregated using XMLAGG:
XMLAGG(
XMLELEMENT(
NAME "element_name",
XMLATTRIBUTES(expression AS attribute_name),
value_expression
)
)
This combination of XML functions allows you to generate an XML representation of the pivoted data, which can then be processed further to extract the required values for the final result set.
Example
Suppose you have a table called sales_data with the following structure and data:
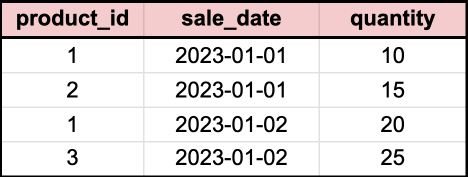
To perform a dynamic pivot on the sales_data table to show the total quantity sold for each product on each date, you can use the following query:
WITH
pivot_columns AS (
SELECT DISTINCT
sale_date
FROM
sales_data
),
xml_pivot AS (
SELECT
product_id,
XMLELEMENT(
"columns",
XMLAGG(
XMLELEMENT(
"column",
XMLATTRIBUTES(sale_date AS "date"),
quantity
)
)
) AS xml_data
FROM
sales_data
GROUP BY
product_id
)
SELECT
product_id,
EXTRACTVALUE(xml_data, '/columns/column[@date="2023-01-01"]/text()') AS "2023-01-01",
EXTRACTVALUE(xml_data, '/columns/column[@date="2023-01-02"]/text()') AS "2023-01-02"
FROM
xml_pivot;
This query generates the following dynamic pivoted output:
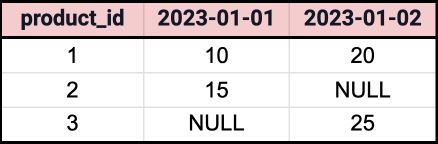
The example above demonstrates how XML functions can be used to create dynamic pivot queries in Oracle, enabling you to handle various data scenarios without having to know the column names in advance.
Dynamic Pivot using REF CURSOR
A REF CURSOR (Reference Cursor) is a data type in Oracle PL/SQL that enables you to create a pointer or a reference to a result set (query output) from a SELECT statement. REF CURSORs are useful in situations where you need to pass query results between PL/SQL blocks, functions, or procedures, and they provide flexibility in working with dynamic SQL statements, like dynamic pivoting.
There are two types of REF CURSORs:
- Strongly-typed REF CURSOR: A REF CURSOR type that is defined with a specific record structure (record type) that matches the structure of the result set it will reference.
- Weakly-typed REF CURSOR: A REF CURSOR type that is not restricted to any specific record structure, allowing it to reference result sets with different structures.
The difference lies in how the REF CURSORs are defined and used.
A strongly-typed REF CURSOR is explicitly associated with a specific RECORD type, which means that the structure of the data being fetched is known at compile time. This can provide some advantages, such as better error checking during compilation and potentially better performance.
A weakly-typed REF CURSOR, on the other hand, is not associated with a specific RECORD type. It can be used to fetch data with different structures at runtime. This provides more flexibility, but at the cost of weaker compile-time error checking.
In the context of dynamic pivoting, weakly-typed REF CURSORs are commonly used, as the structure of the result set can change based on the data being pivoted.
Example and use cases
Suppose we have a table named sales_data with columns product, region, and sales. We want to create a dynamic pivot that shows the total sales for each product by region.
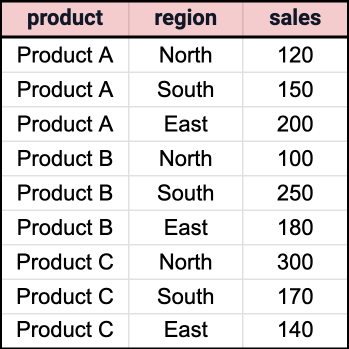
First, let's create a weakly-typed REF CURSOR type:
DECLARE
TYPE RefCurTyp IS REF CURSOR;
ref_cur RefCurTyp;
pivot_query VARCHAR2(1000);
product_name sales_data.product%TYPE;
sales_total NUMBER;
BEGIN
-- Generate the pivot query dynamically
pivot_query := 'SELECT * FROM (
SELECT product, region, sales
FROM sales_data
)
PIVOT (
SUM(sales)
FOR region IN (' || /* Add the list of regions dynamically here */ || ')
)';
-- Execute the pivot query and open the REF CURSOR
OPEN ref_cur FOR pivot_query;
-- Process the result set
LOOP
FETCH ref_cur INTO product_name, sales_total;
EXIT WHEN ref_cur%NOTFOUND;
-- Display or process the pivoted data
DBMS_OUTPUT.PUT_LINE('Product: ' || product_name || ', Sales: ' || sales_total);
END LOOP;
-- Close the REF CURSOR
CLOSE ref_cur;
END;
The dynamic pivot will produce the following result:
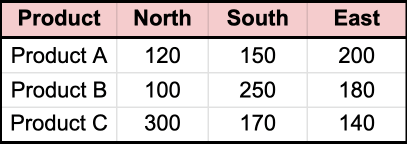
Next, example of using a strongly-typed REF CURSOR with the same sales_data table:
First, we need to define a RECORD type and a REF CURSOR type:
DECLARE
TYPE sales_data_record IS RECORD (
product VARCHAR2(20),
region VARCHAR2(20),
sales NUMBER
);
TYPE sales_data_ref_cursor IS REF CURSOR RETURN sales_data_record;
Next, we create a procedure to fetch the data from the sales_data table and return it as a dynamic pivot using the REF CURSOR:
CREATE OR REPLACE PROCEDURE dynamic_pivot_sales_data(p_cursor OUT sales_data_ref_cursor) IS
BEGIN
OPEN p_cursor FOR
SELECT product, region, sales
FROM sales_data;
END dynamic_pivot_sales_data;
Now we can call the procedure and fetch the data using the REF CURSOR:
DECLARE
sales_data_cursor sales_data_ref_cursor;
sales_data_row sales_data_record;
BEGIN
dynamic_pivot_sales_data(sales_data_cursor);
LOOP
FETCH sales_data_cursor INTO sales_data_row;
EXIT WHEN sales_data_cursor%NOTFOUND;
-- Process the fetched data row here
DBMS_OUTPUT.PUT_LINE(sales_data_row.product || ' ' || sales_data_row.region || ' ' || sales_data_row.sales);
END LOOP;
CLOSE sales_data_cursor;
END;
The above code declares a strongly-typed REF CURSOR and uses it in the dynamic_pivot_sales_data procedure to return the sales_data table content. Then, it calls the procedure, fetches the data using the REF CURSOR, and processes the fetched data rows.
In the given examples, both the strongly-typed and weakly-typed REF CURSORs are used to fetch data from the sales_data table and process it in the same way. The actual output will be the same, but the way the REF CURSORs are defined and used is different.
Optimizing Dynamic Pivot Queries
When working with dynamic pivot queries, it's essential to optimize the performance to ensure efficient processing of data. Here are some tips to improve the performance of dynamic pivot queries in Oracle:
- Limit the number of columns: Avoid pivoting on a large number of columns, as this can lead to a significant increase in the complexity and processing time of the query.
- Filter data early: Apply filters to the source data as early as possible in the query to reduce the amount of data being processed.
- Use appropriate indexing: Ensure that the source table has appropriate indexes on the columns used for pivoting, filtering, and ordering.
- Leverage materialized views: Consider using materialized views to store precomputed pivot results for complex and frequently executed queries.
- Optimize the pivot logic: Carefully analyze the pivot logic and find opportunities to simplify or optimize it for better performance.
When to use dynamic pivot vs static pivot
Deciding whether to use a dynamic pivot or a static pivot in your query depends on the requirements of your specific use case. Here are some guidelines to help you make this decision:
Use a dynamic pivot when:
- The number of columns or values to pivot is unknown or variable at runtime.
- The pivot values are subject to change, and you want to avoid hardcoding them in the query.
Use a static pivot when:
- The number of columns or values to pivot is fixed and known at the time of query development.
- The pivot values are unlikely to change, and hardcoding them in the query is acceptable.
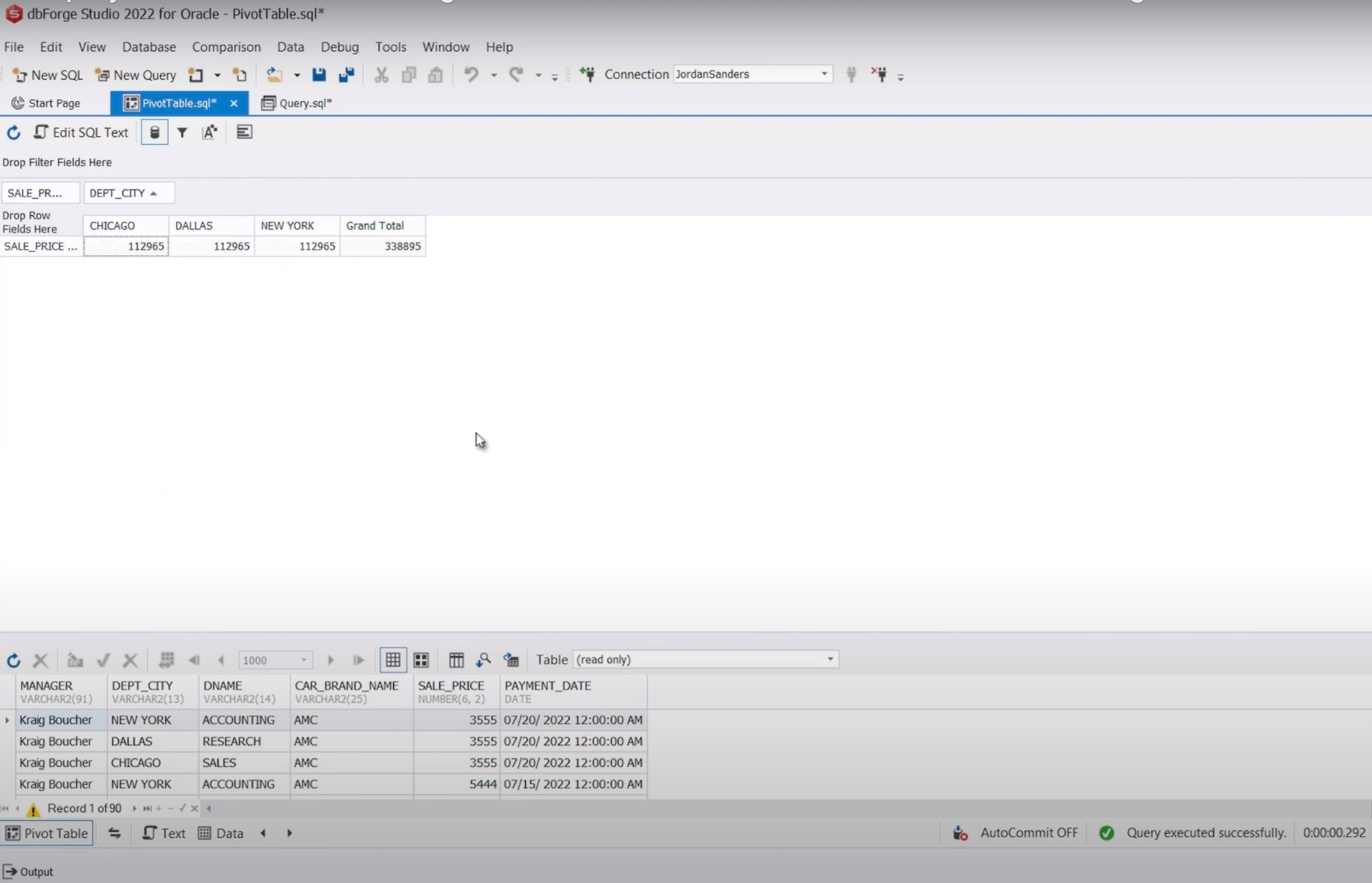
(Pivot Table feature in dbForge Studio for Oracle)
In general, it's best to use a static pivot whenever possible because it typically provides better performance and simpler query development. However, dynamic pivoting is a valuable technique for handling cases where the pivot values are not known in advance or subject to change. If you need more information about static pivot and its usage, you can refer to the ‘Oracle PIVOT’ article.